
13 tracks (32 minutes) of dungeon synth. Mixed and mastered at Big Name.
13 tracks (32 minutes) of dungeon synth. Mixed and mastered at Big Name.
EXCLUSIVE TRACK STREAM: Bull of Apis Bull of Bronze – Annihilation
Annihilation is the second track to be presented to the world from “The Fractal Ouroboros.” Suffocate O Earthen Lungs; They Now Lungs of Ash was released as a stand alone single on the summer solstice, and is a driving monster of a track. Annihilation patiently builds, spending over six minutes in the process of constructing the mood necessary for the moment of annihilation which comes when the composition explodes into furious oblivion. The build is a wondrous, ambient deconstruction of conscious thought, leading to a deep seated sense of nothingness, a preparation for what is to come. Approach this track with reverence. Let the ambience warm you. Float in it. Let the plucked notes pluck at your subconscious. Allow the whispered rasps to float alongside you. Allow the rhythms to pick you up and carry you towards finality. Allow the annihilation. And then…
Full article here.
Hayduke X of MoshPitNation was kind enough to take the time to interview us and put together a full track-by-track review of our upcoming album The Fractal Ouroboros. The article also serves as the premiere of the album’s second single “Annihilation,” as well as the reveal of the cover art, full track listing, and release date (December 21, 2023 – Double LP Vinyl, Cassette, and Digital on Fiadh Productions in the US & Vita Detestabilis in Europe).
github.com/jonlervold/getproductive-frontend
Get Productive! is a tool for quickly tracking, categorizing, sorting, and filtering all sorts of projects and tasks.
This project arose as the result of personal needs. For years, I have used the whiteboard in my studio/office to keep track of all the things I would like to accomplish. But a whiteboard has a limited amount of space, is a pain to reorganize, and can only be modified if you’re standing right in front of it. That system can make it difficult to figure out what to prioritize. I looked at existing digital solutions but didn’t find anything that really thrilled me, so I spent a little time to make an application tailored to my personal desires.
Projects can be defined/sorted/filtered by:
Filtering criteria can be stacked, so it’s easy to quickly see any combination of properties that the user can think of (e.g. show all projects that have a deadline that have not been started, show all projects that are set to high priority that can quickly be completed, et cetera).
Projects can be marked Completed, sending them to a separate list from the Ongoing projects, or they can be sent to the Trash, from which they can be permanently deleted.
The application has a fully encrypted JWT-based authentication system with the ability to create/verify users and reset passwords via email. I’ve been wanting to learn how to build a secure authentication system from scratch for a while now, so this was a good excuse to take on that technical challenge.
If it looks interesting, create an account and give it a try!

Bull of Apis Bull of Bronze – Suffocate O Earthen Lungs; They Now Lungs of Ash
bullofapisbullofbronze.bandcamp.com
An excerpt from The Fractal Ouroboros, the second call to action by Bull of Apis Bull of Bronze. Over three years in the making, The Fractal Ouroboros is the embodiment of grief, catharsis, and empowerment. It shall be unleashed in time, but for now we offer this piece, "Suffocate O Earthen Lungs; They Now Lungs of Ash", on the Summer Solstice--this day marking 4 years since Offerings of Flesh and Gold was released. Much has changed in these 4 years, but our statements have not. Our hopes have not. Towards a better world. This cycle shall be destroyed, Achaierai // Athshean // Yaeth
This is the first single from our upcoming double LP The Fractal Ouroboros. The album is a beast, clocking in at 74 minutes. Creating it was a lengthy process and I am very pleased to finally be putting a portion of it out into the world. I played drums and mixed and mastered the record.
The full album release date is currently TBD. The vinyl will be out on Fiadh Productions in the US and Vita Detestabilis in Europe.

THEREWOLF has been invited to play a reunion show at the annual Dax Lee’s Barbershop Chili Cookoff at Seventh West in Oakland, CA on Saturday, June 3rd. We will be sharing the stage with our old friends Commissure, whom I have played many times with over the years while in various projects. This will be my first live performance since 2017 and Therewolf’s first show since 2010. All proceeds will be donated to The Homeless Action Center and Punks With Lunch, Oakland homeless-outreach non-profits.

Therewolf was a band that some of my best friends and I formed way back in 2009. We got together in our drummer’s garage and wrote these songs. For our one and only performance, we were lucky enough to be asked to play the final show at the legendary Oddstad Gallery in Redwood City before it was sold to a commercial real estate developer. That space was central to our community — it had hosted hundreds of shows and major bands from all around the world. The energy of that final event was incredible.
For reasons none of us are really clear on 13+ years later, Therewolf disbanded shortly after that show. A few months later, I chose to move to Washington state and everyone else moved on with their respective lives as well.
I was disappointed that we had never recorded what we had created and tried multiple times to get a remote recording project together. I recorded some demos and tabbed out all the songs to preserve the ideas. The first attempt at a proper recording took place in 2011, but the effort fizzled and the session was scrapped before much progress was made.
I spent 2012-2018 running Big Name Recording Studio full time. In early 2018, my wife and I decided that it was time to switch things up and start our family, and we decided that the best path forward was to pack up and move to Colorado to be close to her family. I had greatly enjoyed having such a flexible recording space for so long and was uncertain what the future might hold for me with regard to being able to produce loud music without irritating any neighbors. I had a few loud recording projects that had yet to get off the ground that I felt could be great — I thought, “It might be now or never!” (Thankfully, I did end up finding a great recording space in Colorado.)
So I set up the necessary gear and got to work on those projects before we moved. This is one of those sessions.
Our drummer Mike told me at some point prior to 2018 that if I wanted to make the Therewolf recording happen, I should just play the drums on it, since it would be much easier logistically than having him do it, and because it would probably never come to fruition otherwise. So I did, trying to stay as faithful as possible to what he had written based on our full-band demos from 2009. (I am thankful that he was still able to participate in this release as the artist behind the album cover!) I then recorded my guitar parts and sent the session off to Steve (guitar) and Kol (bass), who recorded in California and Illinois, respectively.
The session sat dormant until 2021 when Albert announced that he had booked a recording session (also in California) and would be tracking his vocals. This was quite a surprise after the long pause and I was really excited when I heard the result.
Of course, soon after that I began my journey into the world of software development. I took about a year where I did not work on music at all, so again the session sat dormant. But finally, in 2023, more than 13 years after writing the songs and more than 5 years after beginning the session, the music is ready to be shared.
There are plans in the works to resurrect the band and perform live again. I’m not sure exactly what my capacity will be in the new iteration of the project due to living in a different state, but I am excited to see what the future holds for THEREWOLF.


Gapless w/ Lyrics on YouTube:
Stream or Download/Purchase (name-your-price) on Bandcamp:
From the video description:
The question of how to use existing MIDI tablature software microtonally has come up regularly in the microtonal communities I participate in. I decided to dive in and see if I could figure it out a way to make it work. I then decided to document every step of the process hoping that it might help some other microtonal guitarists! Quick and Dirty Explanation of How to Do This: - Use loopMIDI to re-route your MIDI from a tab program to a DAW - Create a track in your DAW for each track in your tab - Use a microtonal-capable virtual instrument to retune each track All the Software Mentioned in the Video: Tab Software http://tabit.net MIDI Router https://tobias-erichsen.de/software/l... Digital Audio Workstation https://reaper.fm Microsoft Windows Default Soundfont (gm.sf2) https://musical-artifacts.com/artifac... Virtual Synth with Microtonal Capability https://plogue.com/products/sforzando... Shown Microtonal Scale Generator https://colorhorizons.com Other Microtonal Scale Generators Mentioned https://huygens-fokker.org/scala/ https://sevish.com/scaleworkshop/

TabArea.net has been updated! Over the last few weeks I have spent pretty much all of my free time working on upgrading the site. I am very pleased with the results and hope that this provides utility to those who, like me, still use TabIt.
What’s changed?
Some background and technical info from the GitHub Readme for the project:
TabArea.net was created by using WGET to scrape TabIt.net's Tablature Area. WGET simply starts on whatever link you first give it, converts it to a static HTML file, and adds every link present on that page to a list. It repeats this process for every link on the list until it has found every link on the entire website. For the Tab Area, this process resulted in ~350,000 HTML files, along with the ~44,000 TBT files. Turning a PHP-based site into a static HTML site can break a lot of features. The most sorely-missed functionality of the scraped version was the ability to search. As one would expect, it is much more difficult to find anything on the site without it. In early 2023, I learned how to use Puppeteer and thought it would be a perfect tool to scrape TabArea.net, examine each static HTML file, and create a proper database of all the information present on the site. Once that would be complete, I could build a search function. After announcing these plans, TabIt compatriot Ryan Leber let me know that he had already completed this task with an app he built in Python! He sent me the complete SQL dump and it was exactly what I was planning on creating. That part of the work was already done! Score. Thanks Leber. Once the database was in place, there was still a lot of work to be done. Frontend The TabArea Advanced Search frontend is a React App. This element makes up the majority of the repo. The Advanced Search page is intended to maintain TabIt's classic Web 1.0 aesthetic. I wanted it look like it had always been a part of the site, despite being powered by React. Since the files this app searches can only be used on a desktop computer, it is designed primarily for use on PC. That said, it should still be entirely usable on mobile. Backend The TabArea Advanced Search backend is written in PHP. These files are in the php_backend folder. Other The python_utils folder contains two scripts. The TabArea update plan involved removing various site functions that were no longer operational after the site had been converted to static HTML files. With these broken elements removed, hundreds of thousands of the HTML files serve absolutely no purpose. The first script deletes all the unnecessary files. This was a necessity because my OS gets very unhappy if I try to manipulate a folder of that size using normal methods. It makes sense to run this script first so that the second script doesn't waste time processing files that will just end up deleted. The second script is a find and replace function. The update involved changing identical HTML elements of the remaining 100k files. This removes the broken functions, modifies the header, and adds the new search functions to the sidebar. Imagining changing that many files manually makes my head hurt.

10 tracks (43 minutes) of dungeon synth. Mastered at Big Name.

It is with great excitement that I present my latest work, [escape]!
This album is an exploration of the concept of escaping. Escaping difficult personal circumstances, escaping reality, escaping self-imposed limitations, escaping wider social disaster, etc.
On a lighter note, it also explores the concept of “escaping” the confines of the predominant musical tuning system in the world today.
Like my previous [syzygy] releases [xendeavor one], [ouroboros], and [loiterer], my Yaeth album MMXX, Melopoeia’s ongoing Valaquenta, and my web app Color Horizons, this album explores microtonality, the spaces between the notes found in 12 Tone Equal Temperament (also known as 12 Equal Divisions of the Octave [also known as 12edo]). This release focuses on one particular alternative system, 10 Equal Divisions of the Octave (10edo).
Earlier on in my microtonal experimentation, I commissioned a custom 24edo neck from Metatonal Music. I thought it would be a great way to dip my toes into alternate EDOs — 24edo contains all the normal 12edo notes, plus every pitch exactly in between. I was very happy with the craftsmanship of the custom neck, but I quickly discovered that I found the guitar was pretty difficult to play due to having so many frets to keep in mind (some people can play 31edo guitars with precision, I don’t know how they do it!) Also, most of the new extra notes create rather dissonant harmonies. I was struggling to do anything I found worthwhile with it.

Later, I made [xendeavor one], which had one song in 10edo, The Katechon. While composing that song, I was surprised by how consonant I found the tuning. In my experience, when hearing a new alternative system to 12edo, there’s always an adjustment period — initially the tuning sounds strange, but after listening to it for a period of time it can end up sounding as “normal” as 12edo… just… different. I found my ears normalized 10edo very quickly compared to some other tunings. Later, I made MMXX, where I experimented with 10edo further on the song Rise. Again I was particularly intrigued by it as a tuning.
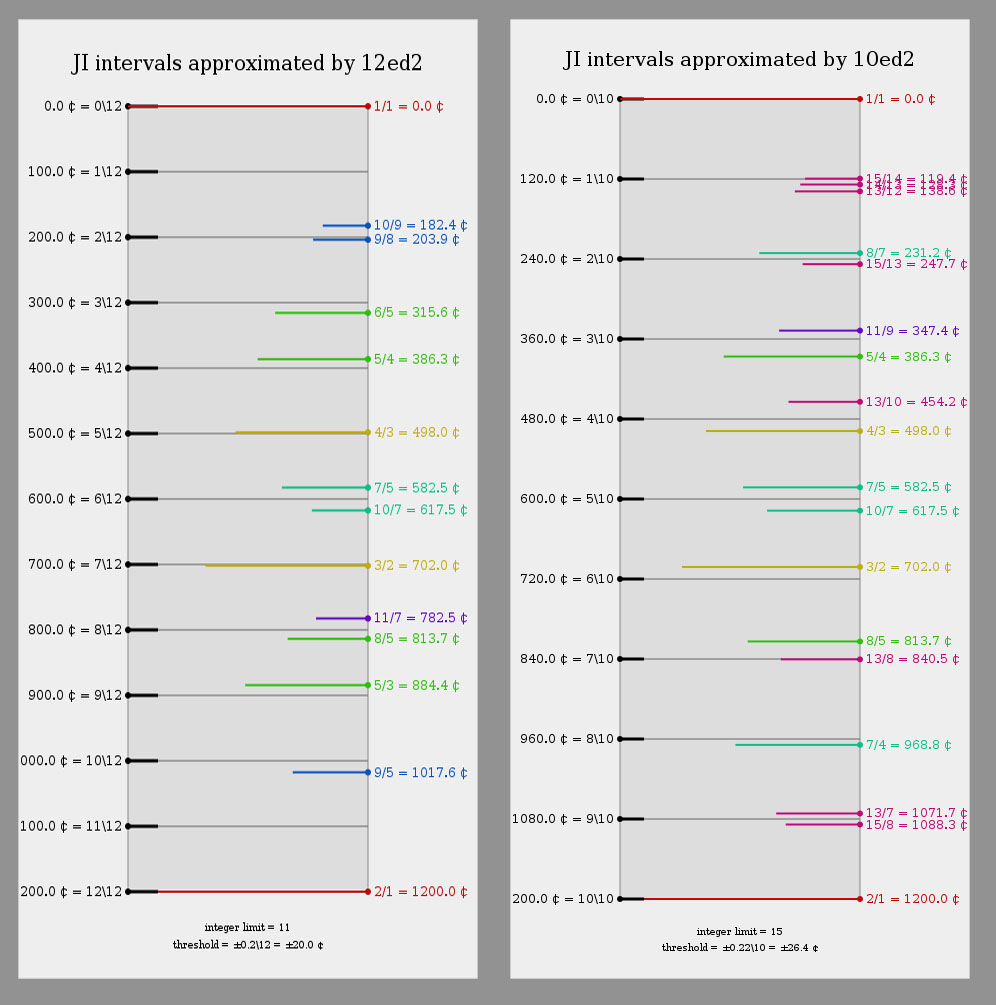
After much consideration, I decided that I wanted to try 10edo on guitar. Firstly, I knew at this point that I loved the sound that 10edo offers. Secondly, where 24edo is more complex due to having twice as many notes, trying 10edo would go the other direction — in theory, it would be simpler to play than 12edo, due to having fewer frets to keep in mind. Thirdly, while playing my 24edo guitar, I found I was always still mentally locked into 12edo thinking due to the fact that all of the 12edo notes are still present. 10edo shares only one interval with 12edo, the 600 cent tritone (which is present in all even-numbered EDOs). Other than that, it offers entirely different potential harmony. (Though due to having 2 fewer frets, it offers a more limited palette of scales with which to experiment…)
Once again, I began the process of getting a custom neck fabricated. As with my 24edo guitar, I was highly pleased with the result. The big difference was that with this guitar, I was immediately able to pick it up and play things that I found usable/worthwhile. The songs on [escape] are each the result of picking a particular mode of a 10edo scale and seeing what comes naturally from exploring it on this guitar.

One interesting side effect of playing the 10edo guitar for a while is that I now find it much easier to play my 24edo guitar than I did before. Where I used to play the 24edo guitar and get stuck thinking in terms of 12edo with extra notes, playing the 10edo guitar helped break the habits built up by more than 2 decades of 12edo guitar thinking. Now that I can comfortably play the 24edo guitar, there will definitely be some quarter-tone work coming in the future that will feature it.
Other Notes:
This is my first complete solo release in over 2 years. Between the pandemic, having a second baby in our family, and spending every single personal free moment I had for a year on a career transition, I had very little time or energy left to produce musical projects. The effects of the pandemic on daily life have lessened, our baby is growing up, and I’ve settled in comfortably in my new line of work. This has left me with much more time and energy to make music. But once I had free time again, I found my musical momentum was low. I have had 6 projects in various stages of completion that have built up (the oldest of which was begun in 2016), but I couldn’t bring myself to actually open Pro Tools and do any work on any of them. This album is an active refreshment of my creative process. I used it to rebuild my momentum. Now that this is done, I am finding much joy in picking those other sessions back up. I look forward to sharing each one of them as they reach completion.
On another note, this is the first release on which I felt inspired to do fully sung vocals since my 2014 math rock offering, Vanishings. For many years I had only felt inspired to make instrumental music or music with harsh vocals… but I’ve always loved singing. Now that I’ve removed that mental block I will definitely be releasing more music with sung vocals as time moves forward. It was especially fun to sing on something microtonal! I’ve wanted to try that since first experimenting with alternative tuning systems.
Thanks to Ron Sword of Metatonal Music for the alternate-EDO neck fabrication, installation, and setup.
Thanks to Jack Shirley of The Atomic Garden for his mastering work on this EP.
Thank you to my wife Laura for the cover art.


Gapless w/ Lyrics on YouTube:
Stream or Download/Purchase (name-your-price) on Bandcamp: